Hello IPFS Community members
I’ve encountered a strange problem that I probably can’t solve on my own, and I’m asking for your help.
I have a set of files in S3 storage, as well as descriptions of those files in a database, including CIDv0 and CIDv1. I checked, I calculate them correctly, they match the CIDs received in IPFS Desktop.
Also, I have several IPFS nodes on debian servers.
Now I’m faced with the problem of adding these files to the IPFS network. Disk capacity for IPFS nodes is small: they are designed for caching, but not for storing all files. All the solutions I have seen open read stream from S3 and pass it to the IPFS library, which completely reads and saves the file to disk, this does not work for me.
I want to make the IPFS client think that it has this file, and at the moment when the file actually needs to intercept a read request, read the file from S3 and give it to IPFS.
The go-ds-s3 plugin for Kubo looks impressive, but I still need a way to add a file to the client by CID - without downloading the data
If you know a better solution to transparently transfer from S3 to IPFS without each IPFS node downloading files, please help me.
if I had to solve this problem, lacking a better idea, I would take boxo/filestore at main · ipfs/boxo · GitHub and hack it into an s3 filestore, where the files are read from s3 instead of a location in the filesystem.
Then I would wrap the s3-filestore in a Kubo plugin and inject it instead of the default (I assume that is possible, or should be made possible).
Thanks for your reply. I found s3ds from go-ds-s3 plugin for Kubo, but haven’t tested it yet. I’ll look at boxo/filestore. Thanks for the --nocopy parameter, I didn’t know that. But downloading the entire volume to each node just to calculate the CID is still expensive.
I’ll try to take a closer look at the Kubo code and add the --cid=someCID option to avoid loading data, or look at how IPFS clients store data about existing files: this could probably work too.
But these are very crooked paths, maintaining the modified code will be very difficult: and data is being added constantly.
A patch with an argument with CID to skip the CID calculation seems to be the only solution (with s3 plugin or patch).
You seem to assume the Cid points to the file. The Cid points to a root dag node with links to other nodes. The leaves of the DAG correspond to file chunks.
This DAG is not in S3 as there are only the files. You may have the root cids but you also need every other cid for every node in the dag of each file.
Filestore works by storing the DAG like normal ipfs but replacing the data in the leaves with path+offset.
Hm. Perhaps I wasn’t precise enough. When loading data into the database and also for saving as S3 metadata I calculate md5, sha1, sha256, sha512. This is required to interact with different services, each using a different method.
When I needed to place data in IPFS, I studied how data is stored in a distributed network. I carefully studied the documentation: https://docs.ipfs.tech/concepts/content-addressing/#cids-are-not-file-hashes
Although without going into detail, I use the library to build a DAG tree and calculate a sha256 hash based on it, represented as CIDv0 and CIDv1. I verified with about 30 files that the hash provided by the original IPFS program matches my expectations.
I store hashes both in the database and in S3 (and I count them, of course, myself).
So I believe that even if I make a mistake in calculating the CIDv0 hash, then IPFS Desktop for Windows and for Linux Ubuntu also makes the same mistake)
I understand that being able to add arbitrary CIDs without checking would probably break the network, but in my case this would be the most optimal route.
I repeat - I know the result of calculations over a large amount of data, and I do not need (and even harmful) the behavior of IPFS, which wants to independently calculate the CID. I’ve looked at the source code and so far I don’t see any other reason to use the data (besides the case from the transfer). But, unfortunately, I did not find a simple way to solve this problem - although it would seem that many organizations use S3 and similar systems as a reliable and distributed data storage and such a problem was bound to arise. This seems strange to me
Also, it makes no sense to store exactly CIDv0 and CIDv1, and not just one sha256 hash from the DAG, but for quick search and testing on small data, I have implemented it this way for now.
I’m not sure how you are verifying the hashes but I think you have gaps in your understanding.
The CID does not contain the sha256 of your file unless your file is <= 256KiB in size and you are using the “raw-leaves” feature.
In all other cases, the CID contains the sha256 of a dag-pb node. If the file has been chunked because it is larger (than 256KiB normally), the CID contains the sha256 of a dag-pb node with links to other dag-pb-nodes that have their own CIDs.
You seem to believe that the CID can point to a file in S3, but the CID actually points to a DAG which has embedded chunks of your file. If your file has several chunks, you will need to store the CID for each chunk too, along with an offset indicating where the chunk starts among all the bytes in your file.
Making a file available on IPFS is not Get(CID) -> <file contents...> but `Get(CID) → Root DAG node. Get(CID_child1) → DAG node… (repeat until DAG is fully traversed). Thus you need to provide the DAG, not the original file. You seem to not be storing the dag-pb DAG as metadata so things won’t work.
I spent quite some time figuring out how this works. The results I get are identical to those calculated by IPFS.
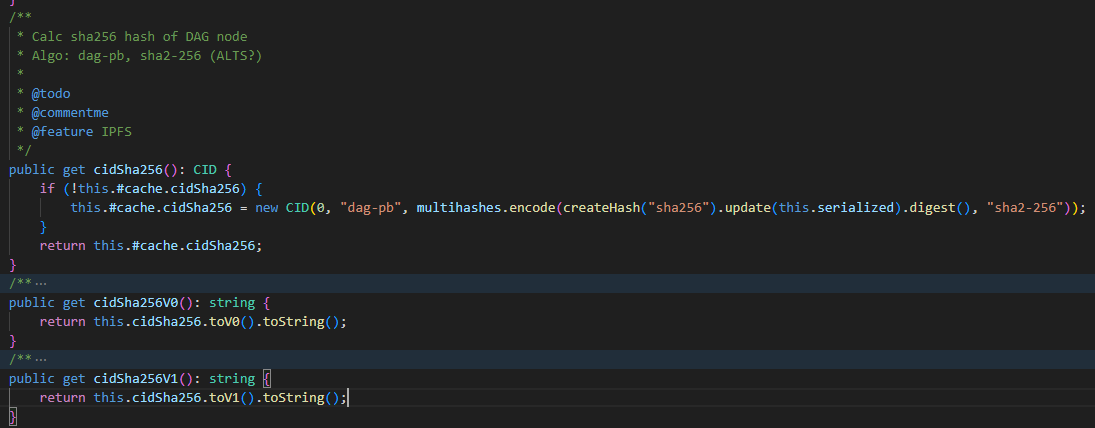
Yes - I build a DAG tree through the library, and then calculate sha256 from the result and create a CID for it. You can see this below in the screenshot. And - yes, I do this for each file in real time, and then enter it both into the database and into S3 metadata (mainly for third-party applications: for example X-Amz-Meta-Cid-Sha256-V0)
The most important thing is that my CID and IPFS Desktop CID are the same, I suppose this should mean that I think everything is correct. If this is not so, then this is very, very strange…
Of course, I do not store the DAG tree, but calculate it only once (upon receiving the file). And I store the hash from it. If the data is immutable, then the DAG tree should be the same, right? This means that the hash from it must also be unchanged.
Now it seems I understand the essence of the problem. No, only one hash (or two CIDv0 and CIDv1). For large files (>256 kb) the problem is reproduced - the hashes do not match. Thanks for pointing this out. Am I correct in understanding that I need to store a separate hash for each 256 kb block? How exactly should this be done, is there an example?
You need to store a separate CID for each 256KiB block, plus CIDs for intermediary DAG nodes (root node, potentially intermediary levels in very large files) and the intermediary nodes themselves.
I’m not familiar with the js ecosystem, but there is “ipfs add” code that does chunking and dag building. You can start there and then probably need to roll your own. The basic pieces you will need are:
Chunks (max 1MiB). Hash them and make a CIDv1 with codec raw and their sha256 (do not wrap in dag-pb). These will be the DAG leaves.
Store the CID of the leave along with an object like { "path": "s3://...", offset: "1234" } in a custom blockstore.
Make a dag-pb root node and add links by hand for every chunk.
Replace the default blockstore with your custom one, which returns the result of reading path+offset from s3 when requesting a leaf.
This assumes you will have no intermediate levels in your DAG and your root can link ALL chunks. That works as long as your root does not go beyond 1MiB in total size. If it does, then you need fully dive and re-use how adding actually works in IPFS.